我最近一直把 OpenClaw 当作日常 AI agent 使用。用下来发现,最需要先解决的不是模型能力,而是浏览器。
原因很简单:agent 如果访问不了原始网页,后面的研究和总结都会出问题。它看起来完成了任务,实际上可能没有读到关键资料,只是退回到质量差很多的来源,甚至直接开始编。
我一开始没有意识到这一点。OpenClaw 做深度研究时,结果总是不太理想。我以为是提示词不好,或者是模型理解不够。后来逐个检查它引用的信息源,才发现真正的问题是:它被很多网站拦在外面了。
一开始怪错了方向
我的运行环境看起来并不像 bot。一台闲置的 MacBook Pro,家里的网络,浏览器里登录了常用账号,也没有什么特别配置。
但是,只要网站有稍微严格一点的 bot detection,就很容易出问题。Google 和 Bing 弹验证码,X 一直显示登录墙,Medium 甚至过不了 Cloudflare。
我先后换过 browser MCP、browser CLI,也改过一些配置。后来还试过换网络和 VPN。结果都一样。
这说明问题很可能不在账号,也不在 IP,而是在浏览器本身。
CDP 的问题
OpenClaw 的内置浏览器基于 Chromium 和 Playwright。Puppeteer、Playwright 这类工具通常使用 Chrome DevTools Protocol,也就是 CDP,来控制浏览器。
问题是,CDP 本身会留下痕迹。自动化工具连接浏览器时,会触发 Runtime.Enable。这个信号可以被页面里的 JavaScript 检测到。Cloudflare 和 DataDome 都会检查这类特征。
IP 和 Cookie 当然也重要,但是在我的场景里,它们不是最先暴露问题的地方。
CDP 也不是唯一的痕迹。自动化库为了工作,通常还会向页面注入一些 JavaScript,比如 window.__playwright__binding__ 之类的对象。反机器人脚本会检查属性描述符和函数签名。如果一个浏览器原生函数的 toString() 不再返回 "[native code]",页面就可以判断它被改过。
这些信号单独看可能不大,但放在一起,就足够让网站把这个浏览器标记出来。
还有指纹识别
另一个我之前忽略的问题是硬件指纹。
浏览器会暴露很多设备相关的信息,比如 WebGL 里的 GPU 型号、Canvas 的像素级输出、屏幕分辨率,甚至音频处理结果。真实机器上的这些值通常是互相匹配的。自动化浏览器如果伪装不好,就会出现矛盾。
例如,Canvas 输出在大量会话里完全一样,或者 user agent 显示 Windows,但 GPU 信息看起来像 Apple。只要这些地方对不上,请求就可能被标记。
我之前一直关注 Cookie、header 和账号状态,忽略了浏览器指纹这一层。
最后起作用的办法
很多反检测工具会在 JavaScript 层面修补这些问题,比如覆盖 navigator.webdriver,或者伪造 Canvas 输出。但是常见的修补方式,bot detection 也能识别。
后来我试到了 Camoufox。它是一个 Firefox fork。至少在我的情况里,它比 Chromium 系工具有效,主要原因有两个。
第一,它不依赖 CDP。第二,它在 C++ 层面修改指纹值,而不是只在 JavaScript 里临时覆盖。这样页面脚本读到这些值时,更像是在读浏览器原生结果。
直接用 Camoufox 的问题
Camoufox 解决了浏览器识别的问题,但直接给 agent 使用并不方便。
它只有 Python SDK。每次浏览器操作,agent 都要写一段临时 Python 脚本,处理方法签名、异步上下文和返回结果。这样做可以跑通,但是代价很高。
每访问一个页面,都会消耗一部分 token 在样板代码上。agent 花在调用 Camoufox 上的精力,甚至比花在真正研究上的还多。
包成 CLI
所以我最后做的事情,是把 Camoufox 包成一个 CLI。
agent 只需要调用 shell 命令,不需要每次临时写 Python。后面有一个 daemon 保持浏览器常驻,也就不用每打开一个页面都重新启动浏览器。
我还加了一个受 agent-browser 启发的功能:返回 accessibility snapshot,而不是原始 HTML。对我常访问的大多数页面来说,这样可以明显减少 token 消耗。我没有做严格 benchmark,但社区里常见的说法是,这种 snapshot + refs 的方式相比 Playwright MCP 可以少用大约 93% 的上下文 tokens。
OpenClaw 通过这个 CLI 跑起来之后,之前那些明显的问题基本消失了。搜索能正常进行,Medium 不再是空白页,X 也不再每次访问都显示登录墙。
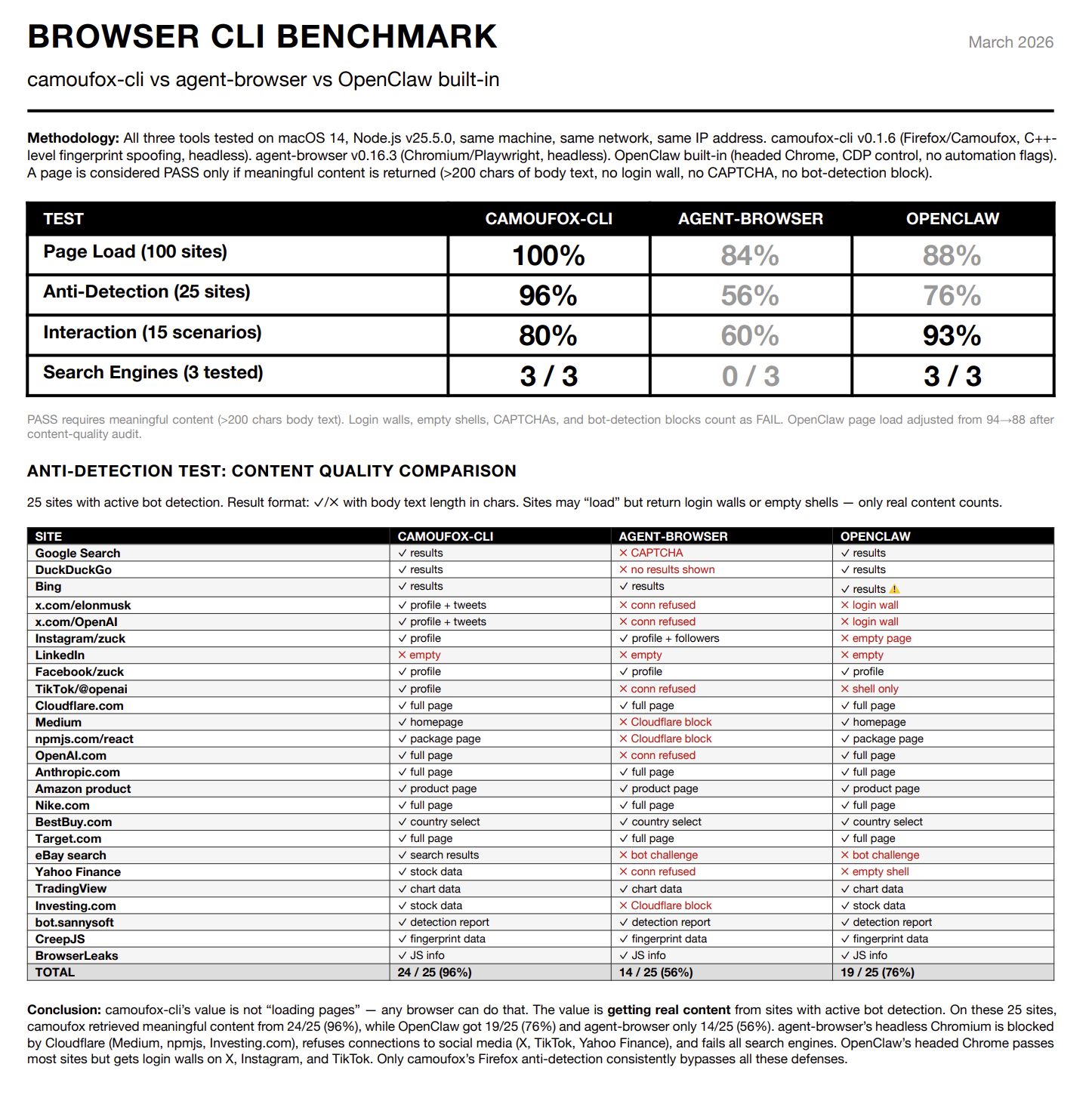
这并不意味着 bot detection 被彻底解决了。它只是解决了我日常使用中最常见、也最影响结果的那一类问题。
这个方案已经跑了几周,我基本不用再关心浏览器这一层。对 agent 来说,这就是比较理想的状态:它应该把精力用在阅读和判断信息上,而不是卡在验证码和登录墙前面。
CLI、skills 和源码我放在这里:camoufox-cli。如果你的 agent 也经常卡在验证码或者空登录墙上,可能能省一点时间。