我日常使用 OpenClaw,前段时间遇到一个问题:深度研究任务的结果总是很差。
排查之后发现,原因是浏览器被各大网站的反机器人系统拦截了。Agent 访问不了正常的信息源,只好退而求其次,去找一些质量差的替代来源,甚至直接编造内容。而这一切是静默发生的,表面上看不出任何异常。
本文记录一下这个问题的原因和解决方案。
一、被拦截
OpenClaw 内置的浏览器基于 Chromium 和 Playwright。我的环境是一台 MacBook Pro,家庭网络,浏览器里登录了各种账号,看上去和正常用户没有区别。
但实际情况是,几乎所有有反机器人检测的网站都会拦截它。Google 和 Bing 弹出验证码,X(原 Twitter)弹出登录墙,Medium 被 Cloudflare 直接拦截,页面无法加载。
我尝试过更换各种浏览器相关的 MCP、调整各种配置,都没有效果。
二、为什么会暴露
问题不在于某个工具或某项配置,而在于自动化浏览器从原理上就会暴露身份。这里有三个层面。
第一层:协议层面的暴露。 Puppeteer 和 Playwright 等工具通过 Chrome DevTools Protocol(CDP)控制浏览器。连接时会触发 Runtime.Enable 命令,反机器人脚本只需要几行 JavaScript 就能检测到。Cloudflare、DataDome 等服务都在检查这个信号。IP 地址和 Cookie 都不重要,控制协议本身就暴露了自动化的存在。
第二层:注入代码的暴露。 自动化工具需要向页面注入 JavaScript 才能工作,例如 window.__playwright__binding__ 等全局变量。反机器人脚本会检查属性描述符和函数签名。如果某个浏览器原生函数的 toString() 返回值不再是 "[native code]",就说明代码被篡改过,足以触发拦截。
第三层:硬件指纹的暴露。 浏览器会暴露大量关于运行设备的信息。WebGL 暴露 GPU 型号和渲染行为,Canvas API 的输出因显卡而异,还有屏幕分辨率、字体指标、音频处理特征等等。每台真实设备都有一组独特且内在一致的数值。
自动化浏览器在这方面容易出问题。比如 Canvas 输出在成千上万个会话里完全相同,或者 User-Agent 声称是 Windows 系统,但 GPU 参数却指向 Apple 硬件。反机器人系统大规模收集这些指纹,只要发现不一致,就会触发拦截。
总结一下:自动化工具在协议、注入代码和硬件指纹三个层面都可以被检测到,仅靠修改配置无法解决。
三、在引擎层面解决
大部分反检测工具在 JavaScript 层面做文章,覆盖 navigator.webdriver 或伪造 Canvas 输出。但如前所述,反机器人脚本可以识别这种 JavaScript 层面的伪装。要真正解决问题,需要在浏览器引擎层面做修改。
Camoufox 是一个 Firefox 分支,采用的就是这个思路。它的做法有几个关键点:
- 在 C++ 层面修改指纹值,伪装的属性在任何检测手段下都表现为原生值。
- 不使用 CDP 协议,页面脚本无法感知自动化代码的存在。
四、让 OpenClaw 用起来
让 OpenClaw 使用 Camoufox 后,Google 搜索、Medium、X 等网站都恢复正常了。
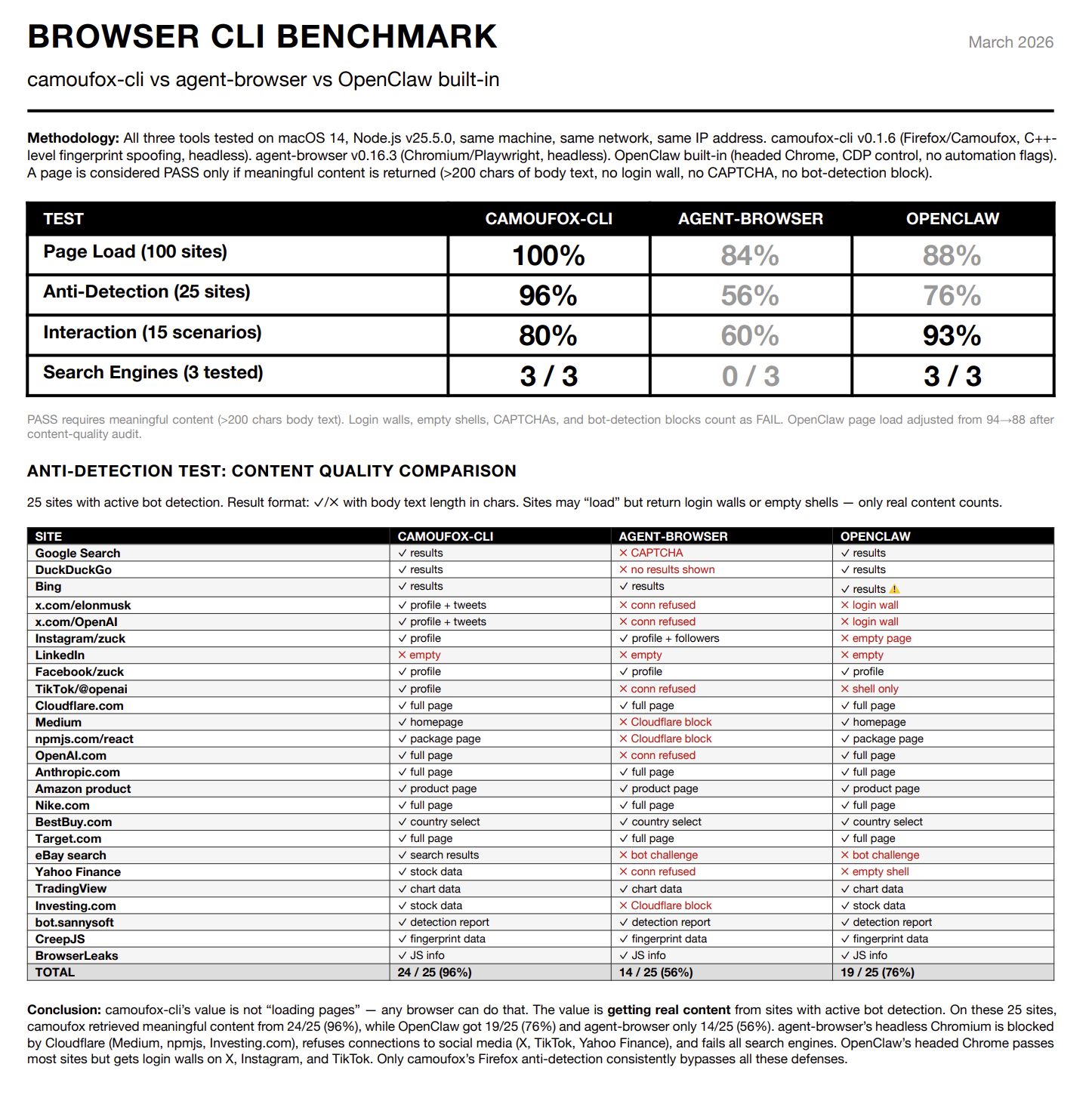
但直接使用 Camoufox 有一个问题:它只提供 Python SDK。每次浏览器操作,Agent 都要生成一段 Python 脚本,处理异步上下文,解析返回结果。光是写这些胶水代码就消耗大量 token。Agent 的主要精力不在研究任务本身,反而在处理这些技术细节。
为了解决这个问题,我把 Camoufox 封装成了一个命令行工具(CLI)。Agent 通过 shell 命令完成页面打开、元素点击、表单填写等操作,不需要生成 Python 脚本。
另外,为了控制 token 消耗,我借鉴了 agent-browser 的做法:CLI 返回的不是原始 HTML,而是无障碍树(accessibility tree)的快照。每个元素带有一个短的 @ref 标签用于后续交互。还有一个只返回交互元素的模式,过滤掉非交互内容,只保留按钮、链接和输入框。一个典型页面,HTML 形式大约 15000 token,交互快照只需要大约 800 token。
这个工具已经稳定运行了几周,深度研究的质量明显提升了,因为 Agent 终于能正常访问那些高质量的信息源了。CLI、Skill 和代码都开源在 camoufox-cli,希望能帮到遇到同样问题的人。