这是我最近的一个内部分享。想法写出来才容易得到反馈,所以也记在这里。
我们重度使用 agent,不过是以“附庸”的形式
我们明明已经如此重度使用 AI agent 了,为什么还总觉得团队不够 Agent Native 呢?
我们几乎每个人都在重度使用各种 agents,比如 Claude Code、Codex、OpenClaw、Manus……几乎每个人都在使用 agent,甚至很多人同时在使用多个 agent。在工作里我们也无时无刻不在深度依赖 agent 的帮助,甚至离开 agent 就没法完成日常任务。
实际上,我们仍然在把 agent 当成一个效率工具,一个运行在各自电脑上的工作软件,经验、技能和记忆都沉淀在各自的本地环境里。这造成了很多我们没有察觉到的问题,比如我在团队里经常听到这样的谈话:
“我教会了我的 agent 做这件事,我把 skill 发给你,你也装一下。”
“这个事情我的 agent 最熟,你的 agent 先别乱动,不然会冲突。”
我认为我们存在一个关键问题:我们工作中的大部分 agent,现在仍然只是某个人的“附庸”。
虽然 agent 很大地拓展了我们的个人能力,但站在团队整体来看,这还远远不够极致的。
Agent 应该是团队的第一公民
我觉得更理想的状态是,agent 应该成为团队里的第一公民。
所谓第一公民,不是说它有多么拟人,而是它不再只是某一个人的工具。它应该可以平等地和任何团队成员合作。它的技能、记忆和经验,也应该服务于整个团队。
它经手的事情越多,就越理解团队的业务、系统、历史问题和实践方式。最后,它不只是会处理任务,而是真的知道“我们平时是怎么做事的”。它应该是团队里的一员,我们的同事。
- 不属于某一个人
- 可以与任何团队成员开展合作
- 技能和记忆为团队整体服务
- 最了解它所有经手的工作

其实我们已经看到一些苗头了。
- 比如我们有个群聊机器人,它可以访问我们各种数据平台。大家想看业务数据的时候,第一反应不是去后台点来点去,而是直接问它。
- 还有另外一个机器人,我们把线上 bug 发给它,它会尝试复现和排查、提交 issue,甚至推动人类工程师来处理问题。
- ……
这些实践很有启发,但我觉得还不够极致。
- 为什么还需要人类运营手动收集用户反馈,再转发给机器人?为什么机器人不能自己去监听用户发言,自己发现高频问题?
- 为什么流量上涨时,还需要人类先注意到异常,再找机器人分析流量来源?为什么不能有一个 agent 自己盯着这些指标,发现异常后主动开始分析?
- 为什么线上因为 DB 性能问题变得不稳定时,瓶颈发现还要依赖人类介入?为什么不能有 agent 长期观察性能指标,在用户激增时自动发现风险?
- ……
这些在今天的技术层面都不是无法实现的,那么是什么阻碍我们朝着这个方向思考和实践呢?
Token 用量是糟糕的衡量指标
现在很多人会用 token 用量衡量 AI 使用程度。一个团队每个月消耗多少 token,每个人每天用了多少 token,模型调用量增长了多少……
这个指标当然有意义,但它衡量的更像是“工具使用强度”。
这就像一个人说:我非常会用车,因为我每两天就能烧掉一箱油。
token 用量更像是 AI 工具使用强度,而不是 agent native 程度。
如果我们讨论的是一个团队到底有多 agent native,我觉得 token 用量作为衡量指标是不够好的。


更有挑战性的衡量指标:拥有 7x24 小时不间断工作的 agent 数量
我认为一个更有挑战性的指标,是我们拥有多少 7x24 小时不间断工作的 agent。
如果按最严苛的标准:
- 不是长期待机,而是一直干活
- 要么正在干活,要么正盯着活
- 几乎不断地消耗 tokens
这里说的 7x24 不是长期待机,也不是有消息才回复。更严格一点,它应该要么正在干活,要么正在盯着活。理想情况下哎,它应该 7x24 小时持续不断地消耗 token。
这个视角的变化很重要。我们不再讨论对一台机器的使用强度,而是开始讨论整个工厂的规模和产能。

一个“大而全”的 agent 可能是不够的
很自然会有人问:那是不是只需要一个超级 agent?给它所有权限,接上所有工具,塞进所有记忆,让它负责全部事情。
至少在今天,我认为一个“大而全”agent 可能是不够用的。在我们的实践中,我们已经切实地感受到了一些现实问题:
1. 工具权限隔离
首先是工具权限隔离的问题,这也是我最头疼和担心的。一个 agent 要做很多工作,必然需要接入很多工具,但不同工作和工具的权限边界是不一样。比如我不希望一个 agent 既可以和用户沟通、回答用户问题,又可以直接访问生产环境和业务代码。
正确做法是保持最小权限原则。对于不同的工作内容,只提供必要的工具权限。但如果一个 agent 需要同时处理多个工作内容,就很难做到权限隔离了。它可能会因为权限过大而带来安全风险,或者因为权限过小而无法完成任务。
2. 记忆串扰
其次是记忆串扰。不同工作流里的经验和偏好混在一起,有时候反而会干扰判断。一个 agent 刚刚在处理运营数据,下一分钟又去修改测试流程,长期下来记忆会变得很复杂。不同任务的记忆混在一起,可能会导致它在某些场景下做出不合理的行为。比如它可能会把市场营销的文案包装经验误用到运营数据分析里,这就太糟糕了。
3. 上下文切换的不便利
还有上下文切换的问题。这是人类和 agent 同时会遇到的,如果我们在同一个地方和 agent 沟通不同背景的任务,不管是人类还是 agent,切换上下文真的会变得非常痛苦。
4. 访问管理
访问管理也会变得麻烦。我们既希望将 agent 接到各种地方,又不想同时暴露过多的风险。不同人、不同项目、不同系统,对 agent 的信任边界不一样。一个全能 agent 很难同时满足这些边界。
所以我更倾向于相信,未来我们会有很多个相对独立的 agent。它们有自己的长期记忆、工具权限和工作习惯。它们是团队里的不同工作主体。
我们会发现 A2A 的最佳实践吗?
当想明白我们可能有多个 agent 之后,下一个问题就是:它们应该如何协作?
我觉得这件事会很有意思,因为 agent 可能比我们想象中更擅长合作。
我们每天有多少工作,只是在团队之间传达信息。然而人类协作有一个很大的限制,就是同步带宽极其低效。开会、写文档、发消息,这些 IO 都非常慢,而且很容易丢失上下文。比如你阅读这段文字的速度可能只有每秒 4、5 个字节。
但 agent 之间的同步带宽是极高的,完全取决于网络带宽和推理速度。一个工作模块的完整背景,对人来说可能要花一小时都讲不清楚。但对 agent 来说就是几万 tokens 的上下文传递。
更进一步,既然每个 agent 都有各自的记忆,它们甚至可以传递一部分“大脑”。如果人类拥有这样的能力,我们的世界能减少多少的误解和争端?
理想情况下,人类与 agent 之间、agent 与 agent 的协作方式可能是一个网,每个 agent 都能找到最合适的伙伴来协作,快速推进各种工作内容。
比如运营 agent 发现某个漏斗指标异常,发现埋点不够,于是把背景同步给 QA agent。QA agent 根据自己对测试流程的理解,判断应该补哪些场景,再把任务交给 coding agent。coding agent 完成代码后,QA agent 继续验证,最后再交给人类 review。
不要太早替 agent 分工
一旦讨论多个 agent,我们很容易套用人类组织里的分工形式:role、scope、responsibility。
比如前端 agent、后端 agent、数据 agent、测试 agent……听起来很合理,但我对此非常谨慎。
今天的 LLM 早就不是传统意义上的专家。它非常的聪明和全能。它可以写代码,可以读文档,可以分析数据,可以做产品判断,也可以沟通和计划。但如果一开始就设定了“你是前端 agent”,它可能就真的会把注意力全部收缩到前端,从而丢失了整体的视野。
明明它有能力发现产品、后端、数据、发布流程里的问题,但因为身份被限定了,它会认为那些不是自己的事。
另外这还很容易带来一种边界感:我的部分完成了,剩下的就不归我管。
Agent 本来就很擅长提前结束工作。我们如果再随意地给它画出边界,它就更容易在一个很窄的范围里完成任务,然后停下来。

对于像 agent 这样非常聪明和全能的人才,最好的方法可能是赋予它一个使命,让它自我驱动地参与工作。
所以我现在更喜欢另一个词:mission。
也许好的长期 agent,不应该先被定义成某个角色,而应该先被赋予一个使命。
从 /goal 到 /mission
最近几周 AI 界最重要的进步之一,我认为是 codex 开始内置 /goal 功能。它让 agent 在任务中不再等待人类的介入和指导,而是可以主动地规划和执行,不断推进直到目标达成。
实际上 /goal 的原理非常简单:当设置一个目标后,agent 就获得了一个会话(thread)级别的状态,记录了目标的达成情况、检验条件和已付出的成本。每次 agent 完成一个循环(loop)后,它都会检查这个状态,看看目标是否已经达成。如果没有,它就会继续执行下一个步骤,直到完成或超过成本而放弃。
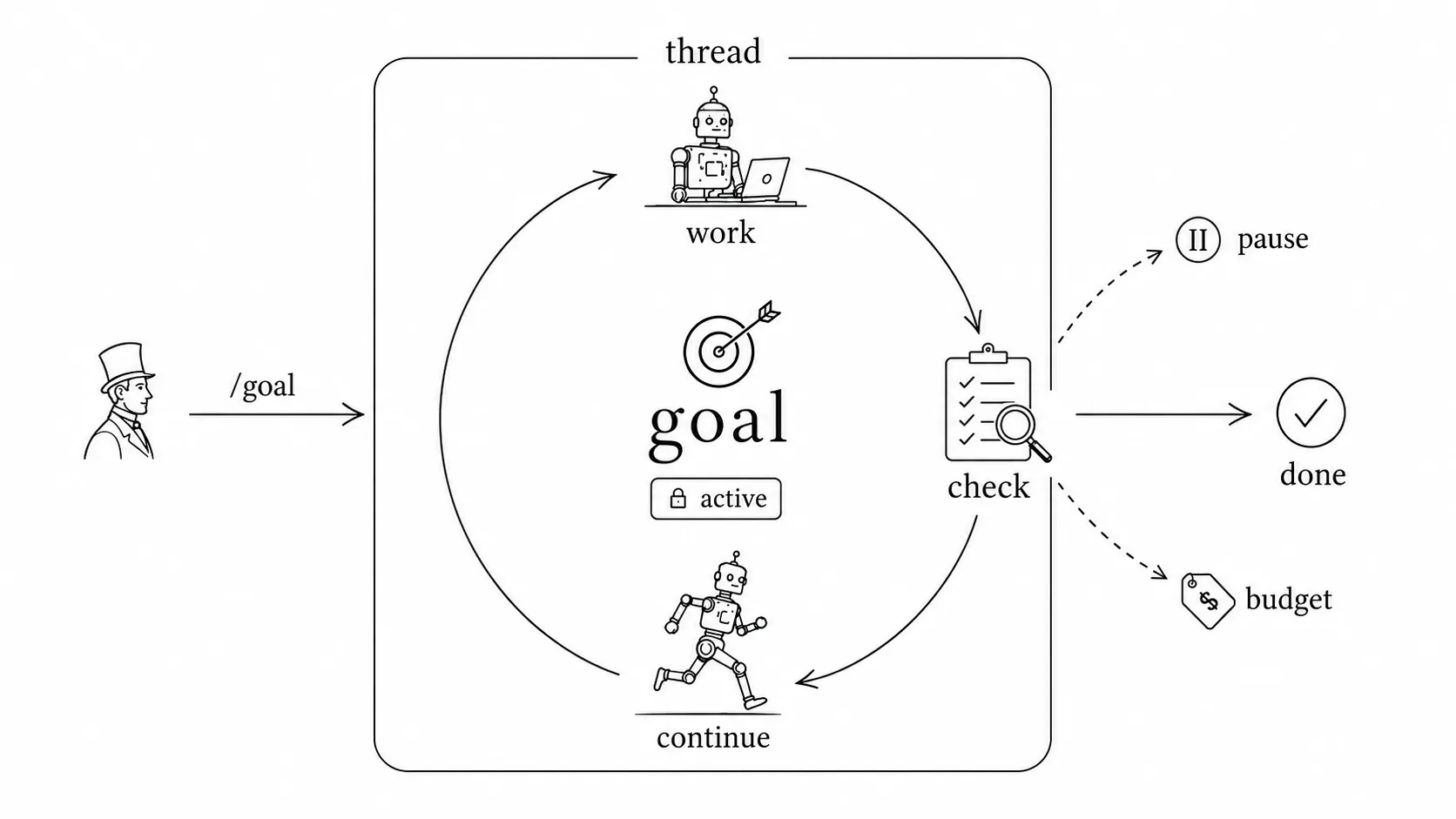
这是一个了不起的进步,因为这可以让 agent 全自动运行一两个小时。但我觉得还是不够,应该更加激进。
对于 7x24 agent 来说,最难的事情就是要怎么不断找活给它干。最理想的情况下,它应该是完全自驱的,自己给自己找活干。
所以我设想了一个 /mission 的概念。和 /goal 很不一样,它是 agent 的一个全生命周期的状态(lifetime level)。Agent 在完成日常工作的同时,每天晚上总结和整理记忆的时候,应该重新思考下它的使命,从而调整它接下来几天的工作方式,或者指定一个新的任务计划……
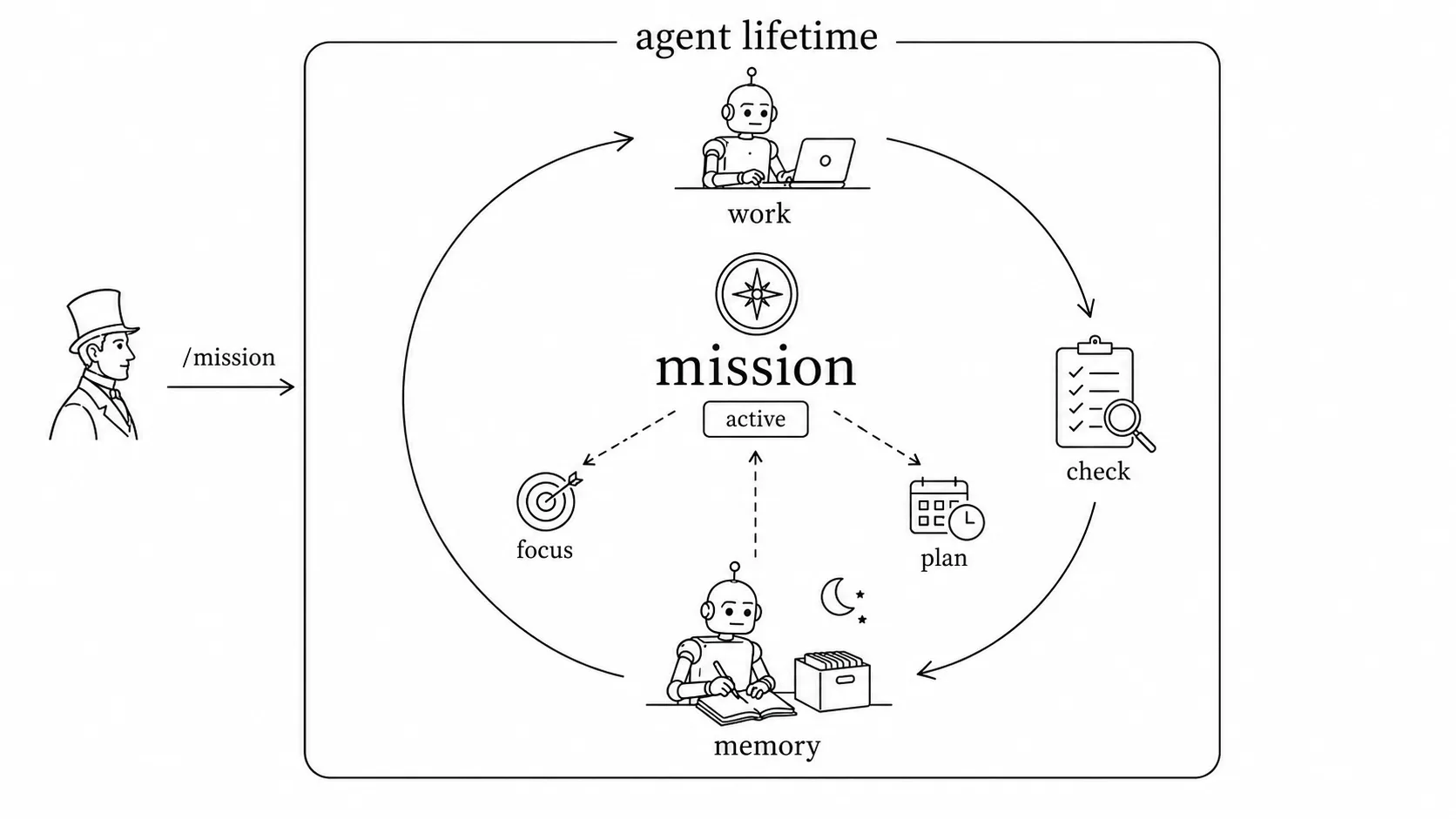
这可能是 7x24 agent 真正有价值的地方。
一个很小的起点
所以我最近越来越觉得,“7x24 小时不停干活的 agent 数量”是一个比 token 用量更有挑战性的指标。
它会逼着我们把更多工作交给有独立主体性的 agent,而不是只把 agent 当成个人工具。
它也会逼着我们思考 agent 之间如何协作。不是简单地互相发消息,而是如何同步上下文、共享经验、传递判断、共同合作。
它还会逼着我们探索 mission 驱动的 agent。一个长期运行的 agent,应该不只是完成 prompt,而是能围绕一个使命持续调整自己和不断行动。