I’ve been running OpenClaw as my daily AI agent, and I’ve made a lot of changes along the way. But the biggest improvement came from fixing the browser.
For weeks, my OpenClaw kept giving me mediocre results on deep research tasks and I couldn’t figure out why. Everything looked fine until I started checking the sources. Turns out it was getting blocked by almost every major site, even with my accounts logged in, and quietly falling back to much worse sources or just hallucinating.
The Problem
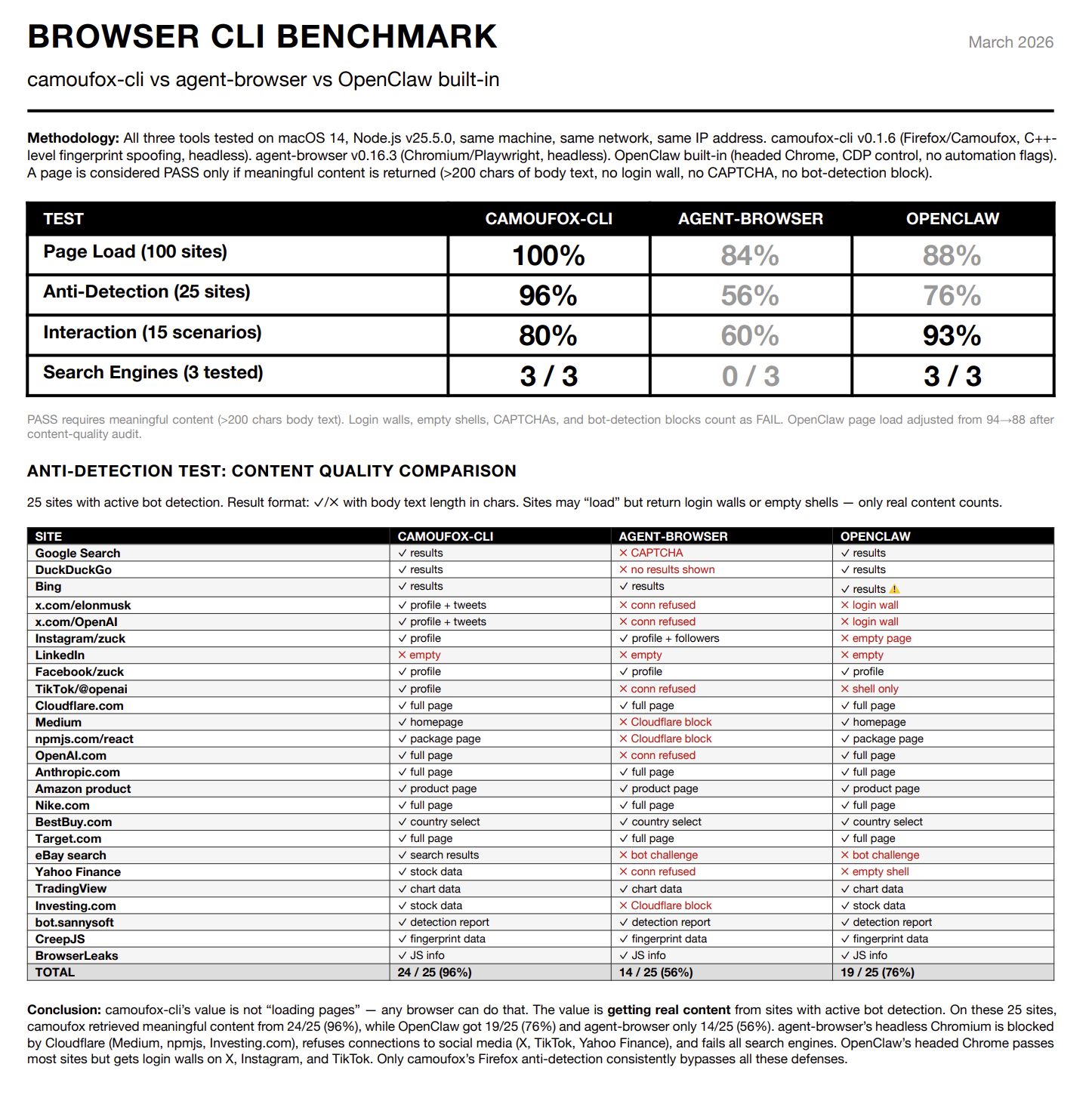
OpenClaw’s built-in browser uses Chromium with Playwright. My setup should have looked human: a spare MacBook Pro on my home network, logged-in accounts, nothing unusual. But anything with bot detection blocked it. Google and Bing threw CAPTCHAs. X showed login walls. Medium wouldn’t load behind Cloudflare. I tried switching browser MCPs, tweaking configurations. Nothing helped.
What I Found
I tried switching networks, VPNs, different browser tools. Nothing. So I went down the rabbit hole of how bot detection actually works, and honestly I was a bit annoyed at how long I’d spent swapping tools when the problem had nothing to do with any of them.
Tools like Puppeteer and Playwright use Chrome DevTools Protocol (CDP) to control the browser. When they connect, a Runtime.Enable command fires. Anti-bot scripts detect this with a few lines of JavaScript. Cloudflare and DataDome both check for it. Your IP and cookies don’t matter — the protocol itself gives you away.
And that’s just one layer. Automation libraries also inject JavaScript into pages to work (window.__playwright__binding__ and similar). Anti-bot scripts catch these by checking property descriptors and function signatures. If toString() on a browser function no longer returns "[native code]", something has been tampered with. That’s enough to flag you.
Then there’s hardware fingerprinting, which I honestly hadn’t thought about at all. Your browser exposes hundreds of data points about the machine it’s running on: GPU model via WebGL, pixel-level Canvas output that varies by graphics hardware, screen resolution, font metrics, audio processing. Every real device has a unique combination of these, and they’re all internally consistent. Automated browsers get this wrong all the time. The Canvas output is identical across thousands of sessions, or the user-agent says Windows but the GPU says Apple. Any mismatch, and you’re flagged.
I hadn’t even considered this one. I’d been focused on cookies and headers while the real problem was three layers deeper.
The Fix
Most anti-detection tools try to fix this at the JavaScript level, overriding navigator.webdriver or faking Canvas output. Anti-bot scripts see through all of that. The fix has to happen at the browser engine level.
After trying a few things, I landed on Camoufox(a Firefox fork). It modifies fingerprint values in the C++ implementation, so spoofed properties look native to any inspection. It doesn’t use CDP at all, and page scripts can’t see the automation code.
I let my OpenClaw use Camoufox, and things immediately started working. Google searches went through. Medium loaded. X showed real profiles instead of login walls.
Making It Work
But actually using it was painful. Camoufox only has a Python SDK, so every browser action required the agent to write a throwaway Python script, figure out the right method signatures, handle async contexts, and parse the results. Each page visit burned tokens just on boilerplate. The agent spent more time writing Camoufox glue code than doing actual research.
So I wrapped it into a CLI. The agent just calls shell commands to open pages, click elements, fill forms. No Python scripts, no async boilerplate. A daemon keeps the browser alive between commands, so there’s no startup cost per action.
I also borrowed an idea from agent-browser to keep token usage down. Instead of dumping raw HTML into the context (tens of thousands of tokens per page), the CLI returns accessibility-tree snapshots. Each element gets a short @ref tag for interaction. An interactive-only mode strips everything except buttons, links, and inputs. A page that costs 15,000 tokens as HTML might cost 800 as an interactive snapshot.
It’s been running for a few weeks now and I haven’t had to think about browsers since. My deep research results are noticeably better now that the agent can actually reach the good sources. CLI, skills, and source code are at camoufox-cli, so nobody has to figure this out the hard way again.