This started as an internal talk I gave recently. Ideas get feedback more easily once they’re written down, so I’m putting it here too.
We lean on agents heavily, but only as personal sidekicks
We already use AI agents a ton. So why doesn’t the team feel more agent-native?
Almost everyone here is a heavy user of one agent or another, things like Claude Code, Codex, OpenClaw, Manus. Many people run several at once. We depend on them all day, and some daily tasks just don’t get done without them.
But we’re still treating an agent as a productivity tool. It’s a piece of software that runs on each person’s own laptop, and its experience, skills, and memory stay in that one local environment. This causes problems we mostly don’t notice. I hear conversations like this all the time:
“I taught my agent how to do this. I’ll send you the skill, install it on yours too.”
“My agent knows this part best. Don’t let yours touch it or they’ll conflict.”
I think there’s a key problem here. Most of the agents in our work are still somebody’s personal sidekick.
Agents have made each of us much more capable. But look at the team as a whole and we’re still leaving a lot on the table.
Agents should be first-class members of the team
What I’d rather see is agents becoming first-class members of the team.
By first-class I don’t mean it acts more human. I mean it stops being one person’s tool. It should be able to work with anyone on the team on equal footing, and its skills, memory, and experience should serve the whole team.
The more it handles, the more it understands our business, our systems, and the way we actually get things done. At some point it’s not just running tasks anymore. It knows how we work, the way an experienced coworker does. It should be one of us.
- It doesn’t belong to one person
- It can work with anyone on the team
- Its skills and memory serve the team as a whole
- It understands everything it has worked on better than anyone

We’re already seeing early signs of this.
- We have a group chat bot with access to our data platforms. When people want to look at business numbers, the first instinct is no longer to click around a dashboard. They just ask it.
- We have another bot we forward production bugs to. It tries to reproduce and debug them, files an issue, and sometimes pushes a human engineer to deal with it.
- And so on.
These are useful, but I don’t think they go far enough.
- Why does a human still need to collect user feedback by hand and forward it to a bot? Why can’t the bot listen to what users are saying and spot the common problems on its own?
- Why does a human have to notice a traffic spike first, and only then ask a bot to analyze where it came from? Why isn’t there an agent watching those metrics and starting the analysis the moment something looks off?
- When the service gets shaky because of a DB performance issue, why does finding the bottleneck still depend on a human stepping in? Why can’t an agent watch performance over time and catch the risk early when usage surges?
- And so on.
None of this is out of reach today. So what’s stopping us from thinking and building in this direction?
Why token usage is a bad metric
A lot of people now measure AI adoption by token usage. How many tokens a team burns per month, how many per person per day, how fast model calls are growing.
That metric isn’t meaningless, but what it really measures is how hard you lean on the tool.
It’s like someone saying they’re great at driving because they burn through a tank of gas every two days.
Token usage is closer to tool-usage intensity than to how agent-native a team is.
If the question is how agent-native a team really is, token usage isn’t a good enough way to answer it.


A harder metric: how many agents work around the clock
I think a more demanding metric is how many agents we have that work around the clock without stopping.
By the strictest version of this:
- Not on standby, but always working
- Either doing work or watching for work
- Burning tokens almost continuously
So 24/7 here doesn’t mean idle standby, and it doesn’t mean replying only when a message comes in. To be stricter, it should either be doing work or watching for work. Ideally it burns tokens around the clock without a real break.
This shift in framing matters. We stop talking about how hard one machine is being used, and start talking about the size and output of the whole factory.

One do-everything agent probably isn’t enough
The natural question: do we just need one super agent? Give it every permission, plug in every tool, load in every memory, and let it own everything.
At least today, I don’t think one do-everything agent is enough. In our own work we’ve already run into some real problems.
1. Tool permission isolation
The first one is permission isolation, and this is the one I worry about most. An agent that does a lot of work needs a lot of tools, but different work has different permission boundaries. For example, I don’t want a single agent that talks to users and also reaches straight into production and the business code.
The right approach is least privilege. For each kind of work, give only the tools that work needs. But if one agent has to handle several kinds of work at once, that isolation gets hard. It can become a security risk because its permissions are too broad, or it can’t finish the job because they’re too narrow.
2. Memory crosstalk
Next is memory crosstalk. Experience and preferences from different workflows get mixed together, and sometimes that interferes with judgment. An agent works on ops data one minute and edits a test workflow the next, and over time its memory gets tangled. Mixed memory can lead to odd behavior in some situations. It might carry copy-polishing habits from marketing into ops data analysis, which would be bad.
3. Context switching is painful
There’s also the context-switching problem. This hits humans and agents alike. If we talk to an agent about tasks with very different backgrounds all in the same place, switching context gets painful for both sides.
4. Access management
Access management gets messy too. We want to connect an agent to many places without exposing too much risk at once. Different people, projects, and systems have different trust boundaries for an agent. One all-powerful agent struggles to satisfy all of them at the same time.
So I lean toward thinking we’ll end up with a lot of fairly independent agents. Each one has its own long-term memory, tool permissions, and working habits. Each one acts as its own contributor on the team.
Will we figure out agent-to-agent collaboration?
Once you accept that we’ll have many agents, the next question is how they should work together.
I think this part gets interesting, because agents may be better at collaborating than we expect.
A lot of our daily work is just moving information between people. Human collaboration has a big limit: our sync bandwidth is terribly low. Meetings, docs, messages. All of that IO is slow, and context drops easily along the way. You’re probably reading this at four or five bytes a second.
Sync bandwidth between agents is much higher. It comes down to network speed and inference speed. The full background of a work module might take a human an hour to explain and still not land. For an agent it’s a context handoff of a few tens of thousands of tokens.
Push it further. Since each agent has its own memory, they can hand off a piece of their “brain” too. If people could do that with each other, how much misunderstanding and conflict would just go away?
In the ideal case, collaboration between humans and agents, and between agents, looks like a web. Each agent can find the right partner and move work forward fast.
For example, an ops agent notices a funnel metric looks off, realizes the tracking is thin, and syncs the background to a QA agent. The QA agent, based on its own grasp of the test process, decides which scenarios to add, then hands the task to a coding agent. The coding agent writes the code, the QA agent verifies it, and a human reviews it at the end.
Don’t divide work among agents too early
The moment you talk about multiple agents, it’s tempting to copy how human orgs split work: role, scope, responsibility.
A frontend agent, a backend agent, a data agent, a test agent. It sounds reasonable, but I’m very cautious about it.
Today’s LLM isn’t a specialist in the old sense anymore. It’s a generalist that can write code, read docs, dig through data, even make a product call. But if you tell it “you’re the frontend agent” up front, it may really pull all its attention into the frontend and lose the bigger picture.
It can clearly see problems across the product, the backend, and the release process. But once its identity is fixed, it decides those aren’t its job.
This also creates a sense of boundary. My part is done, the rest isn’t mine to worry about.
Agents are already good at wrapping up early. If we draw narrow lines around them on top of that, it gets even easier for them to finish inside a tiny scope and stop.

For something this capable and this general, the better approach might be to hand it a mission and let it run.
So the word I keep coming back to is mission.
Maybe the mistake is pinning a long-running agent to a role at all. Give it a mission instead.
From /goal to /mission
One of the more important steps in AI over the last few weeks, I think, is Codex building in a /goal feature. It lets an agent stop waiting for a human to step in and guide it. It can plan and execute on its own, and keep pushing until the goal is met.
The mechanism behind /goal is simple. When you set a goal, the agent gets a thread-level state that records how the goal is going, the check conditions, and the cost spent so far. After each loop, the agent checks that state to see if the goal is met. If not, it runs the next step, until it’s done or gives up after exceeding the cost.
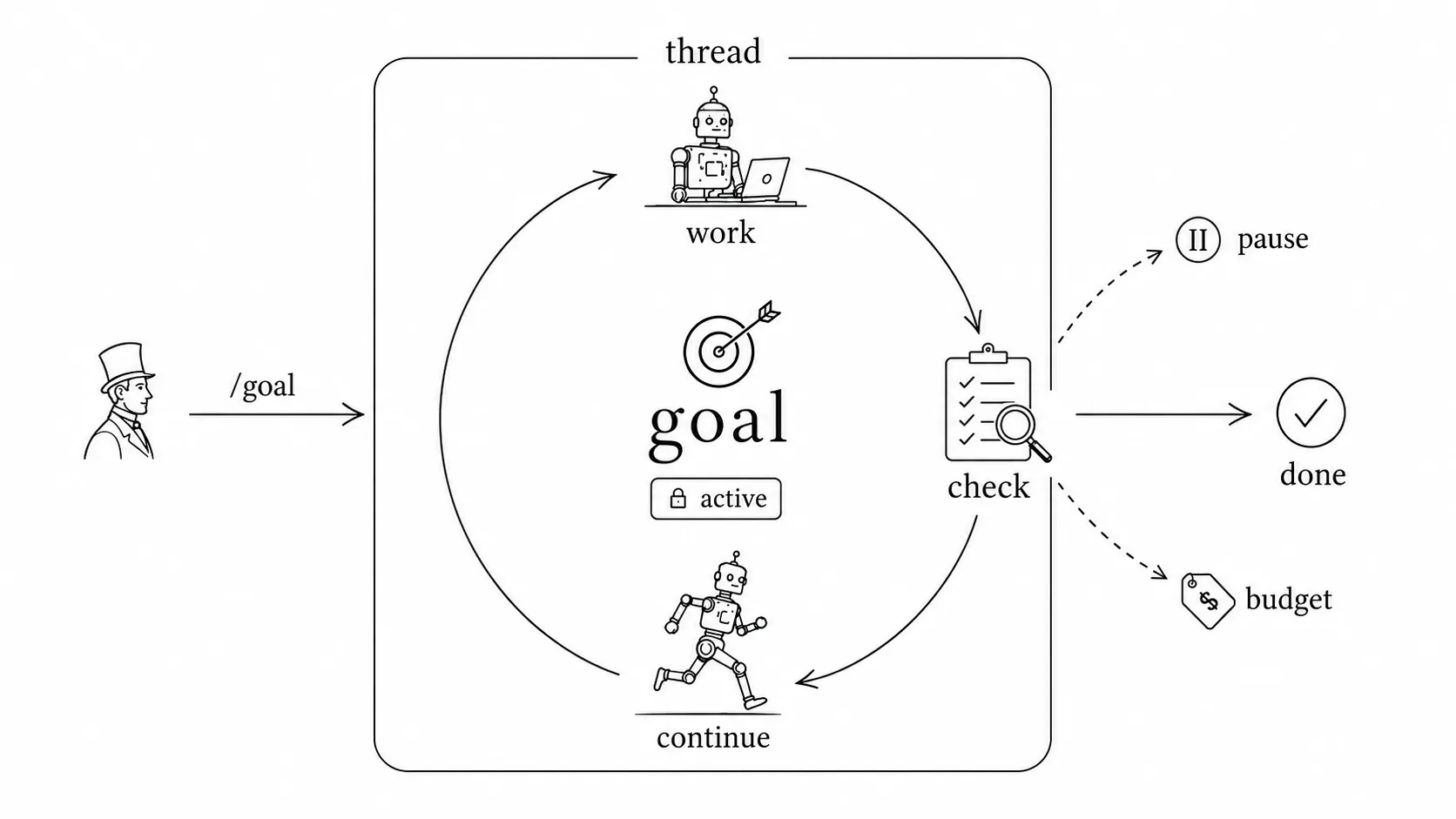
This is a real step forward, because it lets an agent run fully on its own for an hour or two. But I think it should go further and be more aggressive.
For an always-on agent, the hardest thing is figuring out how to keep feeding it work. In the ideal case it’s fully self-driven and finds its own work.
So I’ve been imagining a /mission concept. It’s quite different from /goal. It’s a lifetime-level state for the agent. While the agent does its daily work, every night when it summarizes and organizes memory, it should rethink its mission, adjust how it works over the next few days, or set a new task plan.
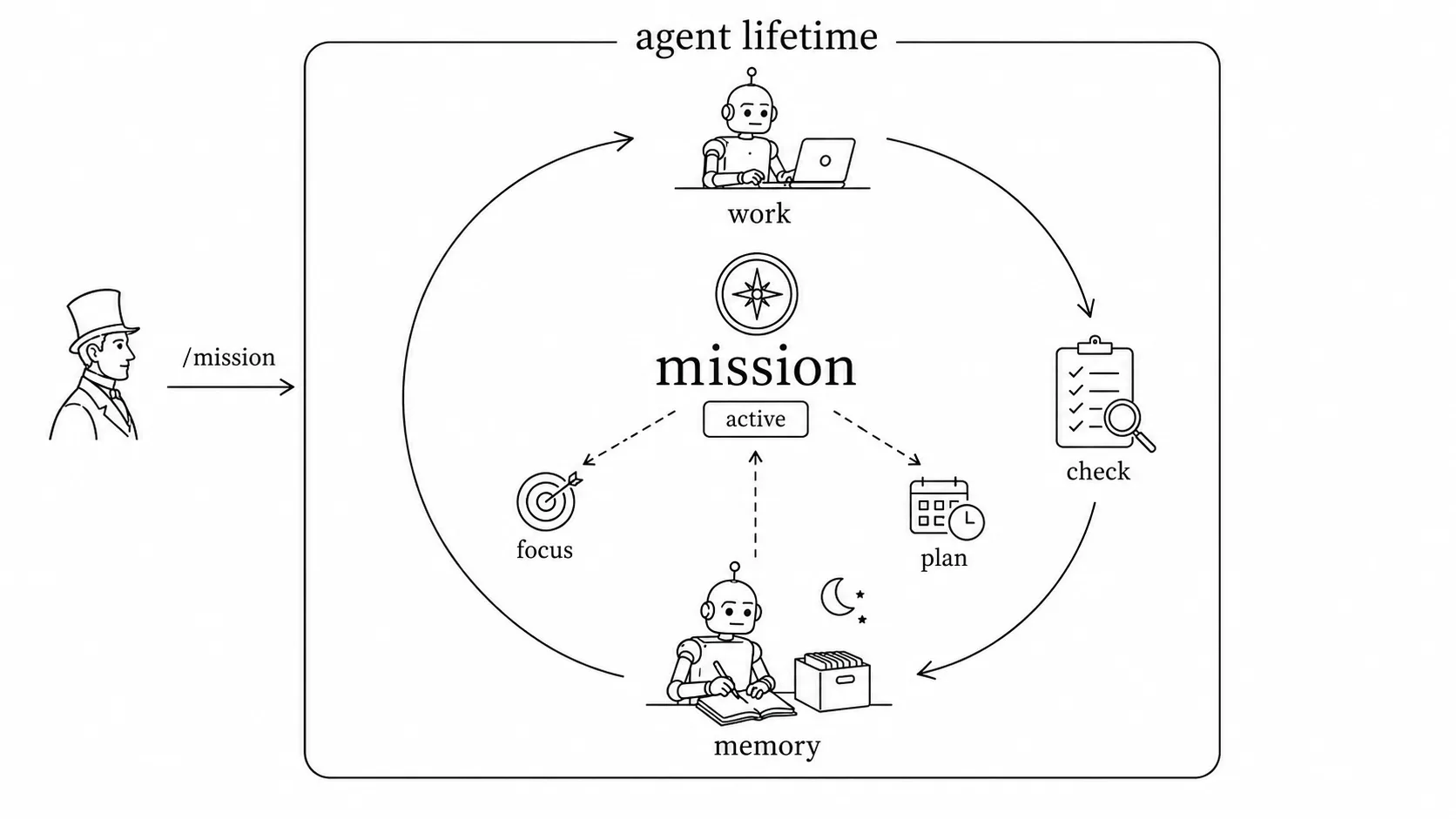
This might be where an always-on agent gets genuinely valuable.
A small starting point
So I’ve come to think “the number of agents working around the clock” is a harder and more useful metric than token usage.
It forces a few things. We’d have to hand real work to agents that have their own agency, not keep them as personal tools. We’d have to get serious about how agents actually collaborate, not just pinging each other but syncing context and passing judgment along. And mission-driven agents stop being a side experiment. A long-running agent that just finishes a prompt isn’t the point. The point is one that keeps adjusting itself and keeps moving, around a mission.