背景
最近我们公司陆续推出了几款新游,在上线当天就异常火爆。因为我们服务支持了游戏中的某个不起眼的小功能,所以这次游戏发布也给我们的服务带来了不少的挑战。其中有个消费者服务在线上出现了严重的OOM(Out-of-Memory)问题,导致系统与游戏业务之间出现了数据同步的延迟。我帮忙排查了这个问题,并很快进行了妥善的处理和修复。
出现问题
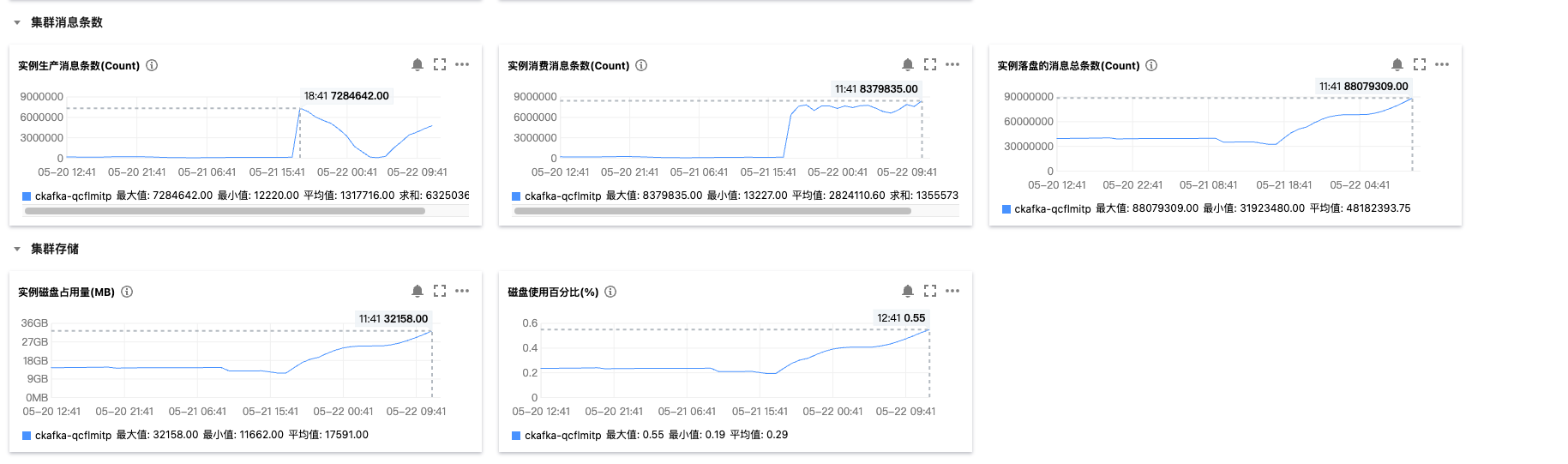
在游戏发布的当晚,峰值时我们每小时有 723 万条 Kafka 事件被创建,消费者服务需要及时地处理这些数据,然后传递给游戏项目组。而此时我们却收到了消费者服务 pod 频繁重启的告警……
诊断问题
我第一时间查看了 k8s 的事件记录,原因是容器因超过内存限制而退出重启(证据一)。究竟是内存配置不够,还是服务存在内存泄露问题,作出判断前还需要看监控指标。
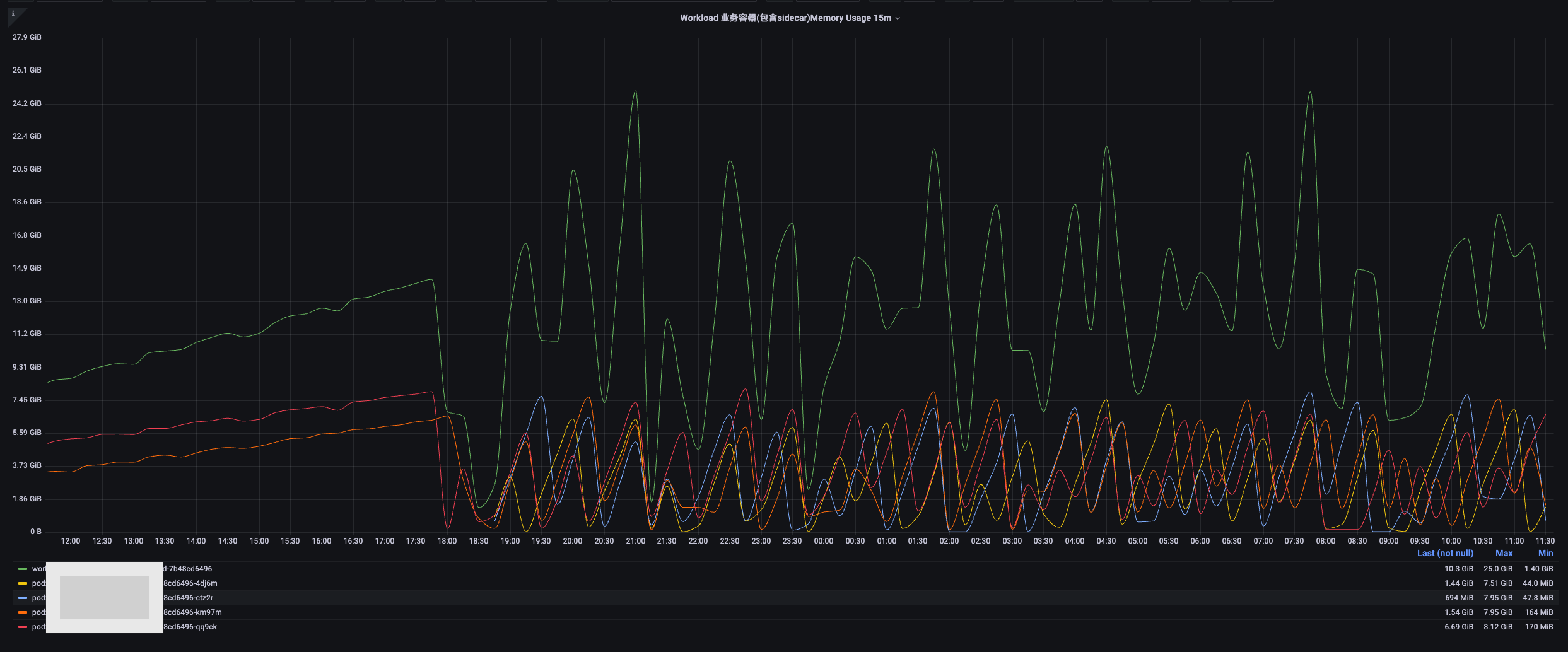
从资源监控上看:
在闲时,每个 pod 内存都在随着时间而增加,并且没有持平和减退的迹象。这正是内存溢出的常见迹象。(证据二)
当游戏发布后大量流量与事件涌入,指标也立即呈现出了剧烈的周期性波浪,表明此刻每个 pod 的内存快速飙升、又因为达到限制而被重启……这个过程反反复复,也印证了线上问题的实际表现。(证据三)
这时候已经可以确信线上问题是因为内存溢出导致的,那么应对方案也确定了。
紧急应对
应对这类线上问题,首先要立即有效地降低负面影响。这是我当时给出的临时方案:
- 将部署的内存限制提高四倍
- 将 pod 数量规模扩大四倍
这样即使线上内存溢出问题依然存在,也能尽可能地缩短服务 OOM 和 pod 重启导致的消费延迟。而且更重要的,这么做也可以为我们接下来的定位修复提供足够的时间和线上环境。
定位问题
从监控指标上看,很明显内存溢出问题很久之前就存在了,只是在这波流量中更加显著地暴露了出来。
接下来要定位内存泄露的原因,首先要获取服务内部的数据指标,尤其是最关键的 heap 打点。好在 Golang 本身的工具链非常成熟,我直接选择了官方的 pprof 工具。
1. 接入 pprof
接入 pprof 有两种方式,一是在服务中直接启动 pprof 的接口服务:
| |
或者在原有服务中额外地添加 pprof 接口:
| |
如果你第一次使用 pprof,请注意要确保相关的路径( /debug/* )不对外网暴露,否则可能会泄露技术数据。
2. 导出 heap 文件
在终端连上某个 pod,导出 heap 文件
| |
3. 本地分析 heap 文件
将 heap 文件下载到本地,进行可视化分析
| |
在 MacOS 第一次做可视化分析时,可能会需要安装本地依赖:
| |
问题分析
我每隔一段时间都在同一个 pod 中打点一个 heap 文件。通过对比,我发现 ccache(*Cache) restart 的内存消耗随着时间不断膨胀,显得非常可疑。
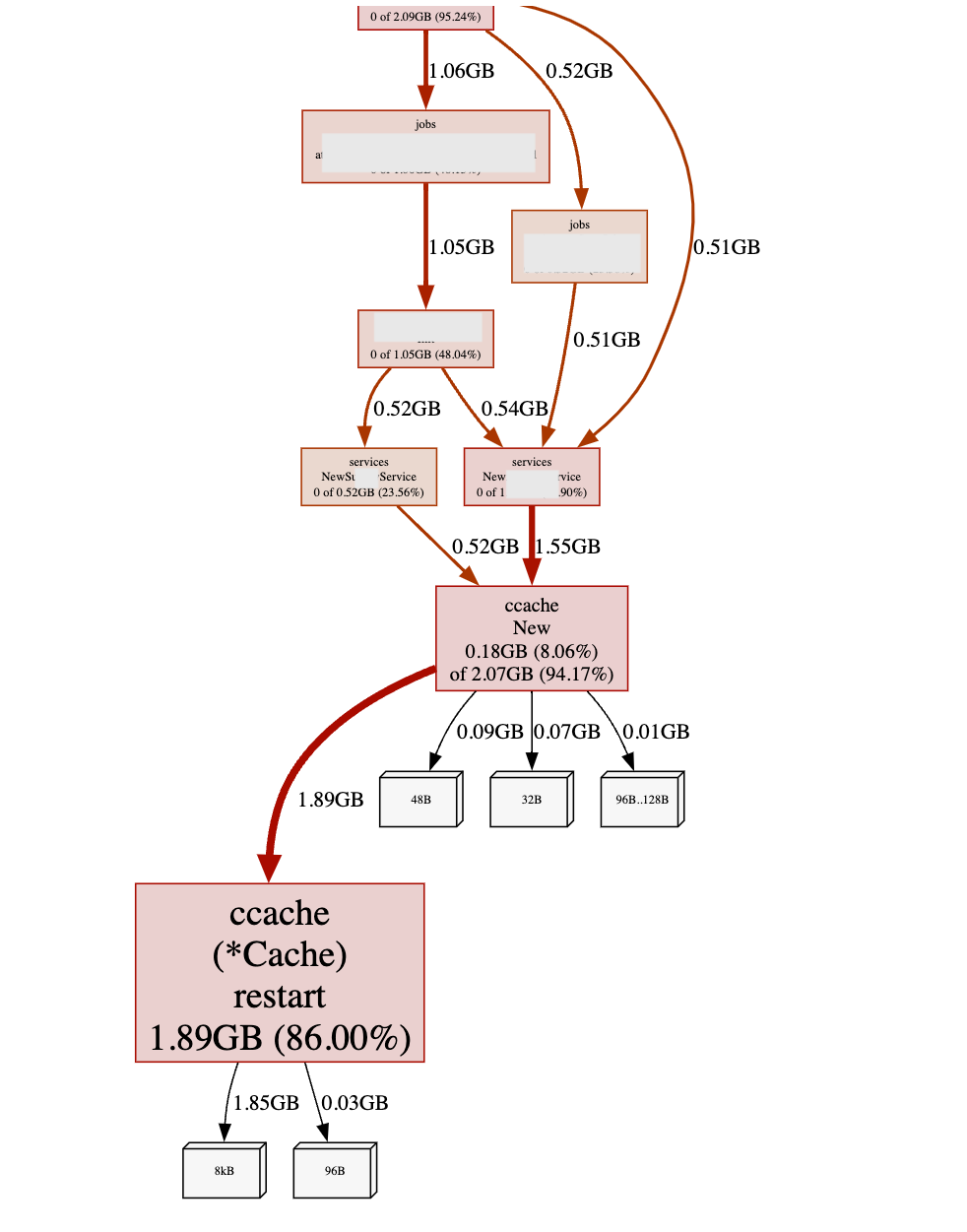
这个 ccache 实例是某个 service 实例中包含的,只是用来缓存哪些 ES index 是否存在。按道理这个实例不应该使用这么多的内存。
我还在 ccache 的 GitHub 仓库中到了一条 issue: https://github.com/karlseguin/ccache/issues/74 。虽然这不是我们问题的原因,但是作者在评论中提到了一个很重要的信息:ccache 初始化后会在后台运行一个 goroutine,实例不再需要时,需要手动地调用 stop() 方法进行清理。
我联想到这个仓库的代码风格,很快就猜到了原因:
消费者需要调用 Service 中的方法。在每次消费事件时,同事们为了方便都会直接初始化一个 Service 实例:
| |
每消费一个事件都初始化一个新的 Service 实例,而每个 Service 实例都包含一个新的 ccache.Cache 实例,而每个 ccache.Cache 都有一个后台运行的 goroutine……这真是一个经典的 goroutine 泄露导致内存泄露的问题!
问题修复
为这个 Service 加上了手动清理后,线上的内存溢出问题也就消失了。
同时,这个问题也隐含了另外一个遗漏,即这个项目的实例初始化和依赖管理机制还比较原始,依然采用人工初始化的方式。这么做虽然很简单,但是在系统比较复杂时,很难有效地正确管理每个实例的生命周期,这也就导致了本次某个 Service 频繁被初始化、却又忘记清理的问题。
我后来的建议是引入 wire + newc 的依赖注入方案,这样所有实例依赖都通过初始化时作为参数传入,而冗长的初始化代码完全交给自动生成,又能减少人工维护的易错性。
这个方案其实已经在我们团队的诸多项目里得到充分验证了,好像刚好就这个系统因为太老而没有改动,正好趁这次问题推进一下哈哈~
总结
其实我写这篇博客时觉得有些无聊,因为 Golang 线上内存泄露问题的排查是非常成熟和套路的,以至于让我怀疑有没有必要为此特意写一篇博客。但我觉得过程中的很多做事方式是值得分享的,而且这些只能在具体事例中才能更好地体现:
- 先判断线上发生了什么问题,寻找数据证据(比如到底是内存配置不够、还是内存溢出)
- 找到问题后,第一时间应该先寻求临时解决方案,降低线上负面影响
- 根据数据排查问题原因:大胆假设、小心取证
- 除了修复问题,还要反思在未来如何避免